ThunderNet
这篇paper介绍了一种轻量级的two-stage detector。从速度及表现两方面都超越了SSD这一类one-stage detector。总的architecture仍是标准的two-stage,由backbone提取特征,再由一个RPN输出proposals,根据proposals从feature maps里提取ROI,最后对这些ROI做classification和localization的refinement。但作者通过选用轻量化的backbone,高效的RPN和检测头(detection head)设计以及引入两种新的结构模块——CEM(Context Enhancement Module)和SAM(Spatial Attention Module),大幅度提高了two-stage detector的效率。下图为ThunderNet的整体architecture。
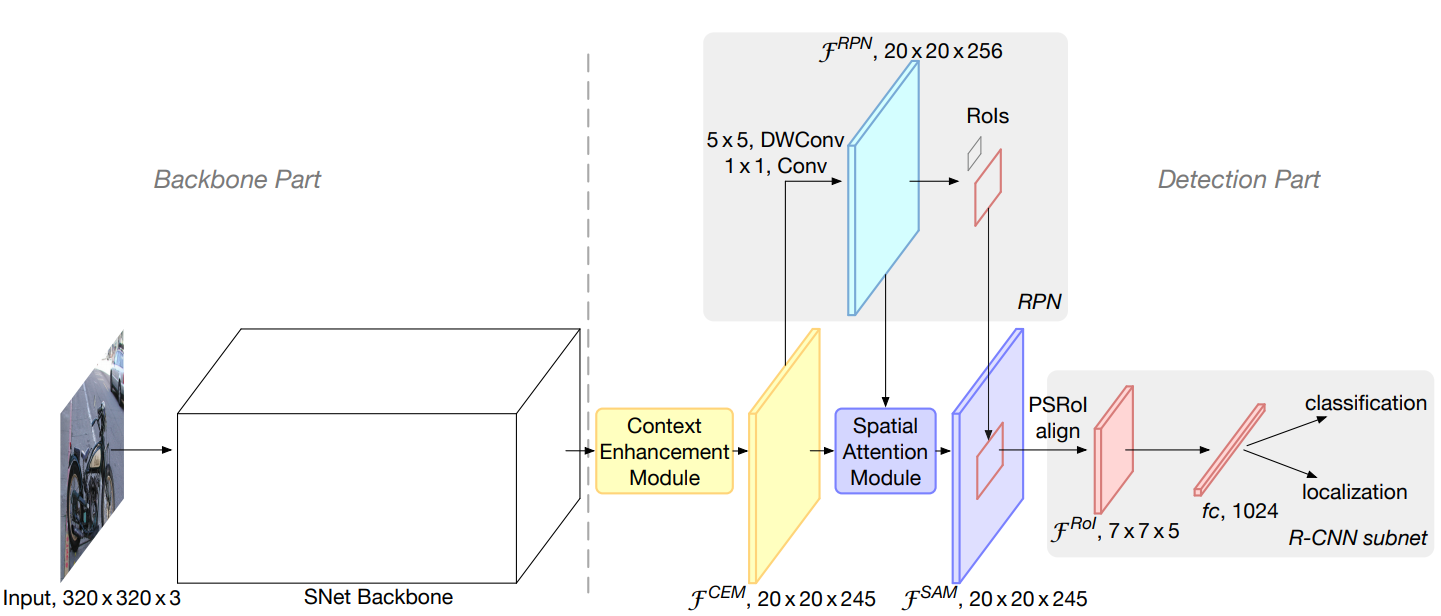
Backbone部分
作者在ShuffleNetV2的基础上专为detection任务定制了一个轻量级backbone,叫SNet。其基本结构模块都相似,但对一些kernel size,channel数以及convolutional layer数进行了调节。这些调节并不是try and fail的结果,而是遵循了三大原则:
输入图片的大小须配合backbone本身的能力。
首先是对输入图片大小的选择。通常two-stage detector的输入图片都会比较大,比如FPN的输入图片为800x像素。大的输入图片可以提高定位的精度,但同时也大幅增加了计算量。而SNet选择了320x320的输入图片,因为作者认为输入图片的大小须配合backbone的能力。对于相对轻量的SNet而言,过大的输入反而会影响表现。作者针对输入图片大小给出了一组实验数据。
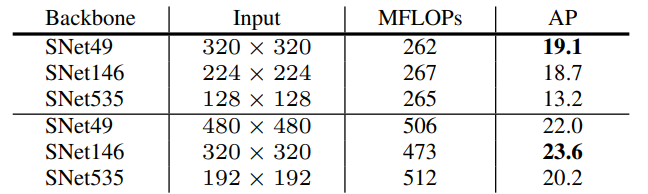
从上半组数据可以看出,当保持MFLOPs基本不变的同时,较heavy的网络加上较小的输入,表现较差。而对比上下两组数据,同样的网络用较大的输入,表现也会较好。其中最深的网络SNet535用192x192的输入相比128x128的输入,AP提高了7%。但严格来说,这张表格并没有提供足够的数据说明继续增大输入,轻量级网络的表现会变差。更多的只是说明了一种trade-off。
backbone网络的receptive field应比一般的classification网络大。
通常大家会直接选用classification网络,替换其输出层来作为detection网络的backbone。但作者指出,相比classification而言,detection任务尤其是其中的localization需要更大的receptive field来得到更多的context信息。因此SNet用5x5的depthwise convolutions代替了ShuffleNetV2的所有3x3 depthwise convolutions,以此将receptive field从121像素提高到了193像素。
localization及classification两种任务需要的信息不同。early-stage features对localization任务比较重要,而late-stage features对classification任务更重要。
对于localization任务而言,空间细节信息很重要,因此更需要early-stage的feature maps。但如果feature map的表达能力较弱,会同时影响两项任务的精度。因此对于一般的classification网络,需要在尽量保持深度的前提下稍微增强early-stage部分。作者通过在early-stage增加channel数以及去掉最后一层convolution或者减少最后一层的channel数来平衡两项任务的表现。
在ablation experiments中,作者尝试加深了模型,并减少了early stages的channel数,模型的 top-1 error降低了,但同时AP也减低了。说明模型在classification任务上的表现变好了,但detectin的能力变弱了,也就是说classification和detection任务两者之间是存在差异的,也就需要不同的backbone设计。
Detection部分
在detection部分,作者对原有的architecture做了3大改动—-压缩RPN和检测头,加入CEM以及SAP。CEM和SAP为作者为了补偿轻量级的backbone和RPN引入的两个新模块。
压缩RPN和检测头
压缩RPN及检测头不但可以节省计算成本,同时也能提高detection的表现。作者认为backbone和检测部分也需要两者匹配。轻量级的backbone与重量级的检测头之间的不平衡不仅会造成浪费,还会提高overfitting的风险。事实上这个现象从另一篇paper “Speed/accuracy trade-offs for modern convolutional object detectors”里就可以看到。
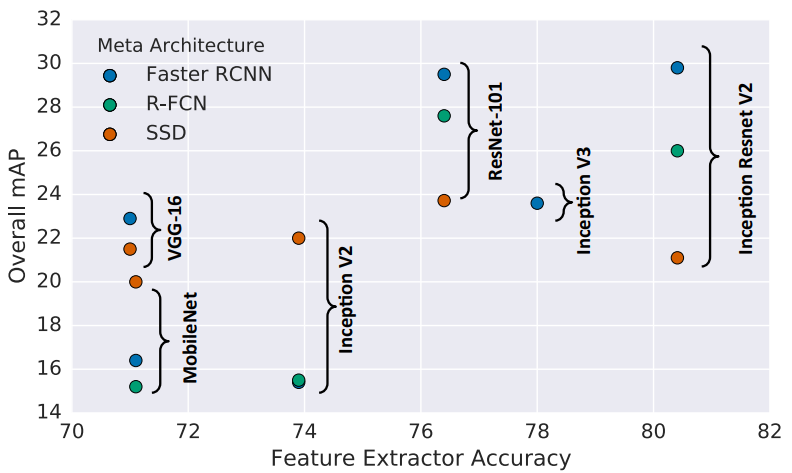
当用MobileNet时,SSD的表现反而比FasterRCNN好。这可能也是backbone和detection head的不平衡影响表现的一个证据。
Ablation experiment中作者比较了large-backbone-small-head以及small-backbone-large-head两种设计,在总的MFLOPs更小的情况下,large-backbone-small-head仍比small-backbone-large-head表现更好,AP高了3.4%。

CEM(Context Enhancement Module)
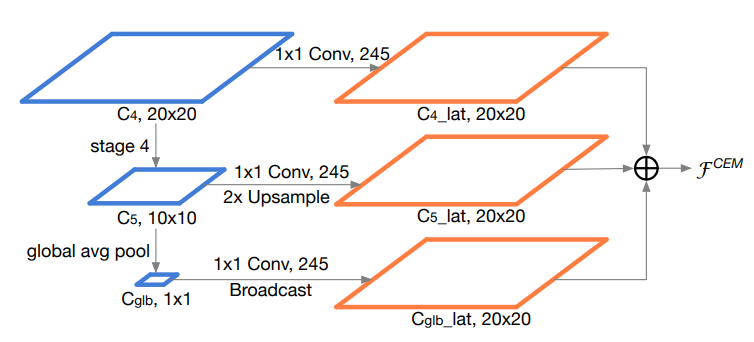
事实上CEM和FPN很相似,思想都是利用multi-scale feature maps。只不过相比FPN,CEM更轻量一些。它只用了backbone的最后两层feature maps,再对最后一层做global average pooling生成1x1的feature map,对三层feature maps分别做1x1的convolution统一channel数之后,再通过upsampling和broadcasting使三层feature maps有一样的大小,最后直接叠加生成最后的输出层。但是paper中提到CEM只引入了两个1x1的convolutions和一个fc层,不太清楚是为什么。
在ablation experiment中,作者证明CEM将AP提高了1.7%,AP50提高2.5%以及AP75提高1.8%。这个结果应该和预期一样,因为早就从FPN甚至UNet开始,就已经证明了multi-scale feature maps的实用价值。
SAM(Spatial Attention Module)
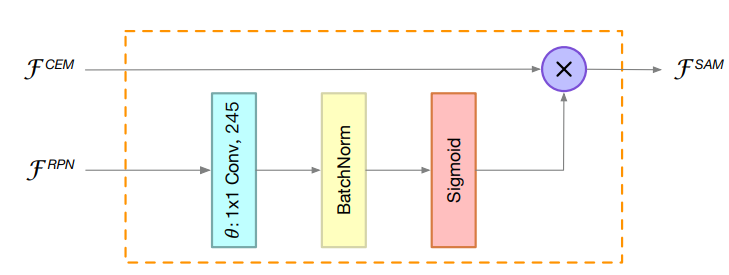
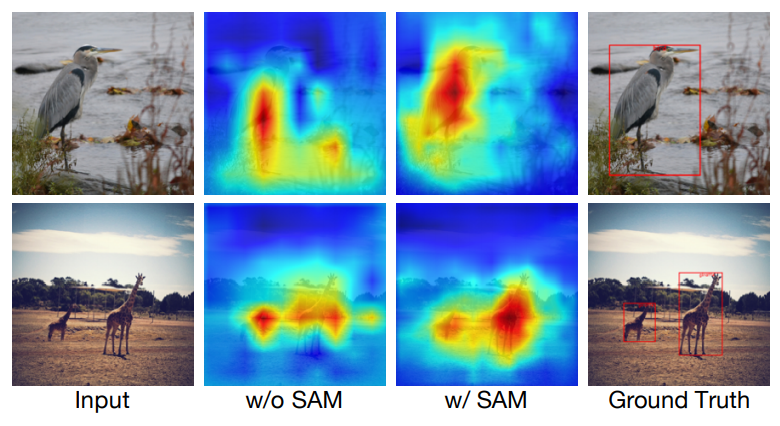
由于backbone和RPN都比较轻量级,以及输入图片比较小,因此用于提取ROI的feature map的表现力依然比较欠缺。作者由此提出了SAM,利用RPN输出的objectness score对CEM输出的feature map进行加权,使前景物品区域有更高的数值。paper中对比了使用SAM前后的feature maps。可以看出加权后的feature map对物体有更强大的表达能力。
另外,由于在SAM中使用到了RPN的输出,相当于在反向传播的时候两次经过了RPN,加强了RPN的gradient的权重,因此使得RPN的训练更稳定。
在ablation experiments中显示,使用SAM将AP提高了1.3%。